
OCRでテキスト検索可能なPDFファイルを作成する
サーチャブルPDF機能について
読込んだ原稿データをPDFに変換するときに、透明なテキストデータを貼付け、テキスト検索が可能なPDF(サーチャブルPDF)を作成できます。OCRの文字認識技術を利用して、スキャン画像から文字情報を自動的に作成します。
本機が認識できる原稿の文字サイズは、次のとおりです。
解像度が200 dpiの場合
日本語:12 pt~142 pt
欧米言語:9 pt~142 pt
アジア言語:20 pt~142 pt
解像度が300 dpiの場合
日本語:8 pt~96 pt
欧米言語:6 pt~96 pt
アジア言語:12 pt~96 pt

参考
- この機能を使うには、オプションが必要です。必要なオプションについては、[ユーザーズガイド [本機について]]の「オプションが必要な機能一覧」をごらんください。
- 次の場合は、文字が正しく認識されないことがあります。
原稿に、複合機で対応していない文字が使われている場合
原稿の言語と異なる言語を選んだ場合
自動でページの向きを補正しないときに、原稿の向きと文字の向きが異なる場合
サーチャブルPDFを作成する
PDF形式でファイルを送信するときに、OCRの文字認識技術を利用して、テキスト検索が可能なPDF(サーチャブルPDF)を作成します。
サーチャブルPDFを作成するときは、ファイル形式として[PDF]または[コンパクトPDF]を選び、[PDF詳細設定]-[サーチャブルPDF]で、次の設定をします。
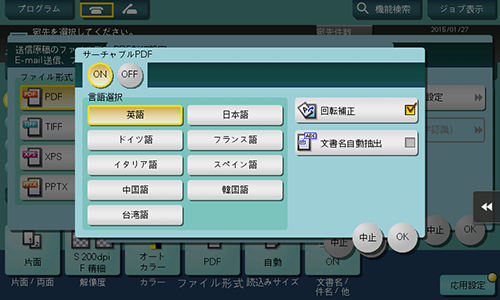
設定 | 説明 |
|---|---|
[ON]/[OFF] | サーチャブルPDFを作成するときは、[ON]を選びます。 |
[言語選択] | OCR処理に使う言語を選びます。 正しく文字認識を行うには、原稿で使われている言語を選びます。 |
[回転補正] | OCR処理により検出した文字の向きに合わせてページごとに自動で回転補正を行うときは、オンにします。 回転補正を行わないときは、指定した原稿の向きが文字の向きと異なる場合に、文字が正しく認識されません。 |
[文書名自動抽出] | OCRの文字認識結果から、文書の名前としてふさわしい文字列を自動的に抽出して、文書名として設定するときは、オンにします。 文書名は、1ページ目の文字認識の結果、日付、時刻、連番をもとにして、自動的に生成されます。 |
参考
- [ファイル形式]で[コンパクトPDF]を選ぶと、[PDF]を選んだときよりも、OCR処理の速度が向上する場合があります。
- デジタル証明書(デジタルID)による暗号化を同時に設定する場合、[回転補正]を設定できません。
- [PDF/A]を[PDF/A-1a]に設定している場合、サーチャブルPDFは設定できません。
- [言語選択]で次の言語を選んだときは、縦書きと横書きを自動的に認識します。
[日本語]、[中国語]、[韓国語]、[台湾語] - [言語選択]で次の言語を選んだときに、原稿の同じページに縦書きと横書きが混在している場合は、どちらか一方の向きで認識されます。
[中国語]、[韓国語]、[台湾語]

 をクリックまたはタップすると
をクリックまたはタップすると になりブックマークとして登録されます。
になりブックマークとして登録されます。